教師無し学習とは?
やっちゃんさん、教師なし学習ってなんすかね?
機械学習の一つだね。
機械学習って、あるデータセットから回帰モデルや分類モデルを作ることでは?
それは教師あり学習のことだね。
教師あり学習、教師なし学習の二つを合わせて機械学習っていうんだよ。
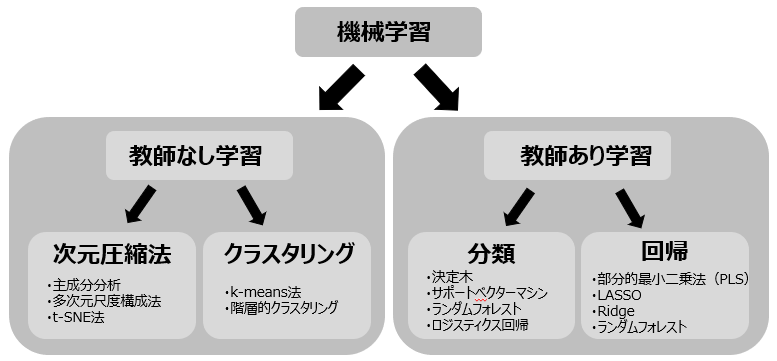
教師あり学習は後輩君が今言ったように「目的変数を求める回帰モデル作ること、またはデータが複数あるグループのうち、どのグループに属するかを求める分類(または判別)モデルをつくること」だね。
だけど手元に何かデータセットがあったとしても、その中に回帰式を作って求めるべき目的変数や分類式を作って1つ1つのデータを割り当てるべきグループすら検討がつかない場合がある。
また、目的変数やグループの種類はわかっていたとしても、それらに寄与する説明変数がわからない時もある。
そんな時にデータマイニングにより自分たちが着目するべき目的変数を見つけること、または判別したいグループをみつけること、そして目的変数や各グループに寄与する説明変数をみつけること、それが教師なし学習だ。
ふむふむ。わかったようなわからんような。。。
具体例を挙げて紹介しよう。
具体例
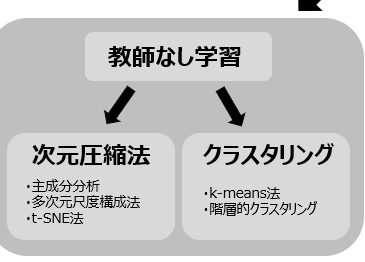
教師なし学習には大きく分けると次元圧縮(削減)法とクラスタリング法にわかれます。そこからさらに、次元圧縮法では「主成分分析、因子分析、多次元尺度構成法、t-SNE」、クラスタリングでは「k-means法、階層的クラスタリング」など様々な手法が存在します。図には記載していませんが、相関解析もそうです。
どの方法も、手元にあるデータセットの中から隠れたグループを探したり、また、ある目的変数(たとえば、ある疾患をもつ人)のレベルや量を特徴づける特徴因子があるかを探しに行くことができます。そして、見つけたグループを判別させるモデル作ったり、みつけた特徴因子(=説明変数)からあるタイプ(例 疾患)のレベルを回帰させるモデルを作ったりするわけです。
分類モデル作成にむけた教師なし学習
例えば1000人の日本人に性格アンケート調査が行われたと仮定しましょう。アンケート結果を解析して、日本人にはどんな性格タイプがあるのか調べて、最終的には性格診断アプリをつくることが目標だとします。
アンケートをとっただけではどんなタイプがあるのかはわかりませんが、教師なし学習の例えば主成分分析を行うことで「自分のことにしか興味を示せない性格、他人にしか興味を示せない性格、自分にも他人にも興味を示す性格、誰にも興味を示さない性格」の4つの性格タイプがあることがわかったりします(あくまで例え話)。
続いて、それぞれの性格タイプにはどの質問項目が寄与されているのかを教師なし学習の因子分析で探しにいきます(あくまで例え話)。
そして主成分分析と因子分析でみつけた複数グループとそれらグループに寄与する説明変数(質問項目)から性格診断アプリに導入する分類モデルをつくっていくわけです。
これが分類モデルを作るうえでの教師なし学習の一例です。
回帰モデル作成に向けた教師なし学習
たとえばある疾患をもつ患者さんと持たない健常者に血液検査をしたとします。血液検査には血中の赤血球量、白血球量、血小板数、鉄、たんぱく量、尿酸値など様々な血中成分の情報が含まれていますが、今回の最終目標は血液検査の結果から患者さんの疾患レベルを推定する回帰モデルを作ることです。どんな病気であれ早期発見することがとても大事ですもんね。
疾患レベルを推定する回帰モデルを作っていくために、まずは教師なし学習の主成分分析や因子分析、そして相関解析などにより血中成分を解析します。そして、健常者に比べて患者さんたちに特徴的に多い/少ない血中成分はどれなのか探しだしていきます。
最終的には疾患レベルに寄与する説明変数(血中成分)から回帰モデルをつくり、血液検査により病気を早期発見する技術を開発していくわけです。
これもあくまで一例ですが、これが回帰モデルを作るうえでの教師なし学習の一例です。
まとめ
いかがだったでしょうか?繰り返しになりますが、教師あり学習に向けて
データマイニングによって自分たちが着目するべき目的変数を見つけること、または判別したいグループをみつけること、または目的変数やクラスターに寄与する説明変数をみつけること、それが教師なし学習です。


コメント