こんにちは、やっちゃんです。
Pythonを使った統計量の算出方法について解説していきます。
用いるデータはKaggleから抜粋した「Dummy Marketing and Sales Data」で学生のデータサイエンス練習用に用意されたダミーのマーケティングデータです。
DataFrame 基本統計量の算出
算術平均値 df.mean()
|
1 |
df.mean() |

カラムごとの算術平均値を算出できます。
1つのカラムだけで良い時はdf[“~”].mean()みたいな感じでdfの後にカラム名をいれてね!
以下同文。
中央値 df.median()
|
1 |
df.median() |
中央値を算出します。
データを小さい順に並べたときにちょうど真ん中となる値のことです。
データを代表を決めるのに算術平均値、幾何平均値、中央値などがありますが
データ分布が左右対称(正規分布)ではなく、左右非対称のときに使う代表値ですね。
データに極端に大きな値や小さな値がある場合、平均値はそれらの影響を受けやすいからです。
分散 df.var()
|
1 |
df.var() |
データのばらつきレベルを表す指標です。
平均値と個々のデータの差の2乗の平均を求めることで算出します。
つまり、平均値から離れた値をとるデータが多いほど分散が大きくなり、
ばらつきが大きいデータと言えます。
標準偏差 df.std()
|
1 |
df.std() |
分散の平方根をとることで算出する値です。
平均値と個々のデータの差の2乗の平均なので、もともとのデータから
どれほど個々のデータが離れているのか感覚的に理解することができません。
ですので、平方根をとることで直感的にデータのばらつき具合を理解しやすくできますね^^
最大値 df.max()
データの最大値を算出します。
|
1 |
df.max() |
最小値 df.min()
データの最小値を算出します。
|
1 |
df.min() |
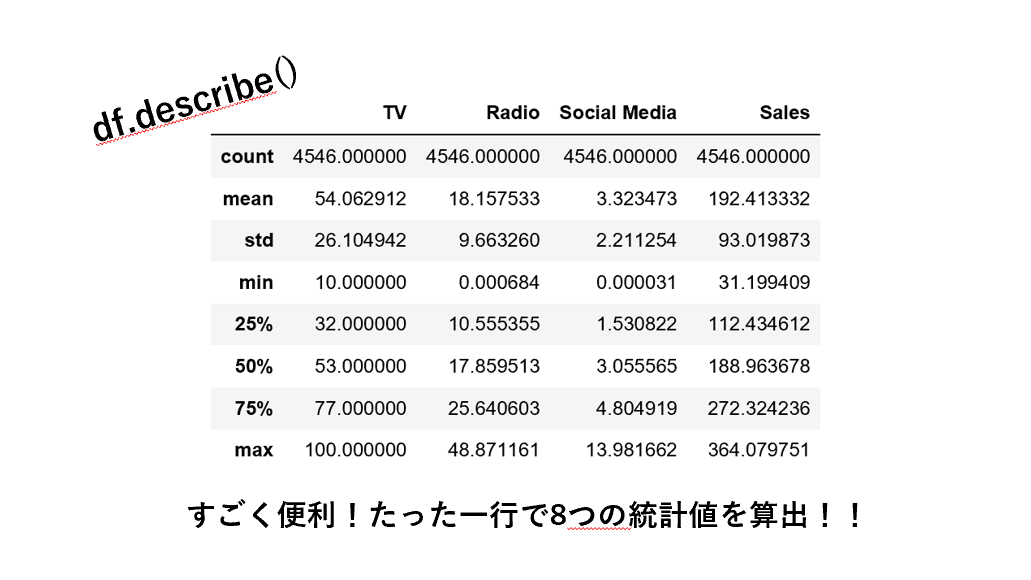
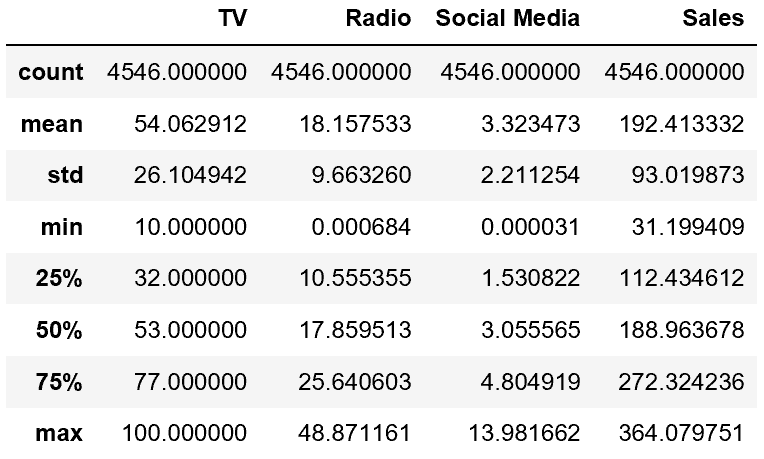
様々な統計量を一気に算出 df.describe() 便利
非常に便利です。
データの要素数、平均値、標準偏差、最小値、
1/4四分位数、中央値、3/3四分位数、最大値を一気に算出してくれます。
|
1 |
df.descrive() |
めっちゃ使えます!
statistics – 数理統計関数
pythonに備わっている統計値を算出してくれるライブラリです!
平均値、中央値、中央値が2つの値の平均で出してる場合の小さいほうの値、
中央値が2つの値の平均で出してる場合の大きいほうの値、最頻値、
母分散、母標準偏差、標本分散、漂分標準偏差などなど出せます。
正味、あまり使わないですが、母分散、母標準偏差をだしてくれるのが便利かな?
とりあえず、今回の
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import statistics mean = statistics.mean(df["TV"])#平均値 median = statistics.median(df["TV"])#中央値 median_low = statistics.median_low(df["TV"])#中央値小さいほう median_high= statistics.median_high(df["TV"])#中央値大きいほう mode = statistics.mode(df["TV"])#最頻値 pstdev = statistics.pstdev(df["TV"])#母分散 pvariance = statistics.pvariance(df["TV"])#母標準偏差 stdev = statistics.stdev(df["TV"])#標本分散 variance = statistics.variance(df["TV"])#標本標準偏差 print(mean) print(median) print(median_low) print(median_high) print(mode) print(pstdev) print(pvariance) print(stdev) print(variance) |
54.06291245050594
53.0
53.0
53.0
43.0
26.10207048068426
681.3180833786088
26.104941837656888
681.4679883474489
といった感じで出してくれます!
終わりに
自分はStatisticsはあまり使わないですね~。
前半部分でお見せしたコードのほうが短くて楽ですし、
なんといってもdf.describe()の楽さは尋常ではないです。
初めて使った時の便利さにはびっくりでした笑。
是非、使ってみてください^^。


コメント