
みなさんこんにちは、やっちゃんです。
本日もPythonを用いたデータの確認方法や加工方法についてご紹介していきます。
今回、デモで用いるデータも内容理解がしやすいように実践的データを用いました。
Kaggleにある「Titanic」です。あの映画のやつですね。
船の甲板でのハグシーンが有名なあのロマンチックなやつです。
またPythonビギナーが機械学習の勉強の初期に使うことが多いデータセットですね。
データの列内容は
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age(年齢)
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(タイタニックへ乗った港)
|
1 2 3 |
import pandas as pd df = pd.read_csv('〇〇.csv') df.head() |

Survived以外の説明変数から、目的のSurvivedが死亡または生存のどちらになるかを
回帰または分類で予測するやつですね。機械学習モデルの作り方はおいおいやりましょう!
列(カラム)内容の確認
csvファイルを読み込んだ後に特定列がどういった内容なのか確認したいときがありますよね。
df[].unique()で確認します
|
1 |
df["SibSp"].unique() |
array([1, 0, 3, 4, 2, 5, 8], dtype=int64)
SibSp – タイタニックに同乗している兄弟/配偶者の数にはどんな値があるかがわかりました。
複数を一気に確認したいときはprintで出力します
|
1 2 3 |
print(df["SibSp"].unique()) print(df["Survived"].unique()) print(df["Sex"].unique()) |
[1 0 3 4 2 5 8] [0 1] [‘male’ ‘female’]
性別はmaleとfemaleですね。
欠損値の確認
isnull().sumでそれぞれの列で欠損値がいくつあるのか、合計を算出できます。
|
1 |
df.isnull().sum() |
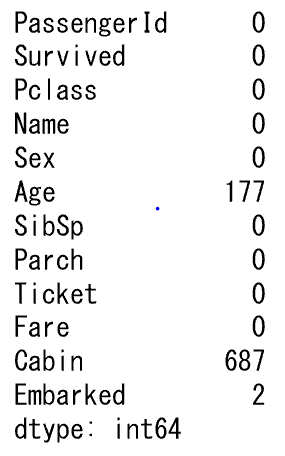
Age、年齢に177個の欠損値、Cabinが687個、Embarkedが2個ということがわかりました。
また可視化用のライブラリのseabornをインポートして、heatmapで作図することで、
データフレームのどの辺に欠損値があるのか視覚的に判断しやすくできます。
|
1 2 |
import seaborn as sns sns.heatmap(df.isnull(), cbar=False) |

白い部分が欠損値がある部分です。
欠損の削除
dropna(how = “any”)で欠損値を含むすべての行を削除できます。
欠損値が削除されたか、isnullで確認しましょう。
|
1 2 |
df = df.dropna(how = "any") df.isnull().sum() |

しっかり欠損値がある行が削除できてますね。
また、欠損値を含むすべての列を削除したい場合は、anyの後にaxis=1を入れてください。
|
1 2 |
df = df.dropna(how='nay', axis=1) df.isnull().sum() |

列で削除できたのがわかります。
欠損値に任意の数を代入
例えば、すべての欠損値に0を代入したい場合、fillna()に0をかちこみます。
|
1 2 |
df = df.fillna(0) df.isnull().sum() |
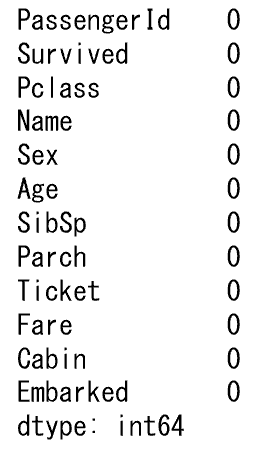
欠損値がないので、すべての欠損値は0に置き換わりました。
任意の列の内容を別の表記にする。(Ex. 文字を数字に)
例えば、今回の性別の男性を1、女性を2として表記しなおしたいときに使います。
df.loc[df[] == “任意の列の任意の要素”, “任意の列の名前”] = 任意の文字か数字
です。
|
1 2 3 |
df.loc[df["Sex"] == "male", "Sex"] = 1 df.loc[df["Sex"] == "female", "Sex"] = 2 df.head() |

maleとfemaleが1と2に変換されているのがわかります。
今後、回帰モデルや分類モデルを作る際に、
文字では説明変数として加えられないので数字に変換するといったデータ加工をよくやります。
覚えておいてください♪
本日は以上です。ご参考になれば幸いです。
何かご質問や、ご教授いただける際にはぜひご連絡ください。
よろしくお願いいたします^^。
タイタニック、久々に見たいな~。


コメント